音声ファイル認識ができません(音声ファイル認識が途中までしか認識されない)
1
利用できる形式が決まっています。下記をご確認ください。
Q:ファイル認識で利用できる拡張子を教えてください
2
ご利用の音声ファイルがネットワークドライブやBoxやOneDrive等クラウドフォルダに保存されている場合、音声ファイルの読み込みが出来ない場合があります。デスクトップ等のローカル環境にファイルを保存してご利用ください。
3
音声ファイルが再生可能な場合は、対象の音声ファイルをMediaPlayer等で再生していただき、その音声を下記の「今すぐ開始」から認識していただけます。

録音前設定のスピーカーで該当の音声ファイルを再生している
イヤホンやヘッドセット等を選択してください。
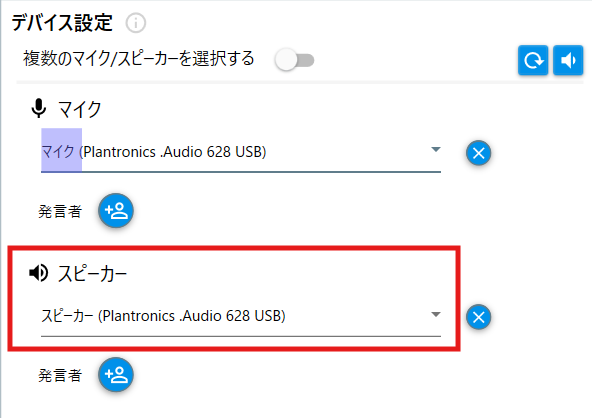
録音開始をしていただくことで音声ファイルの認識が開始されます。
4
音声ファイルが認識できない、再生できないといった場合は、音声ファイル自体の破損が考えられます。再度音声ファイルを作成していただくか、形式を変換(m4aであればmp3等に変換)していただき事象の改善が見られないかご確認ください。※変換ツールの準備が難しい場合は弊社にて対応いたしますのでご連絡ください。